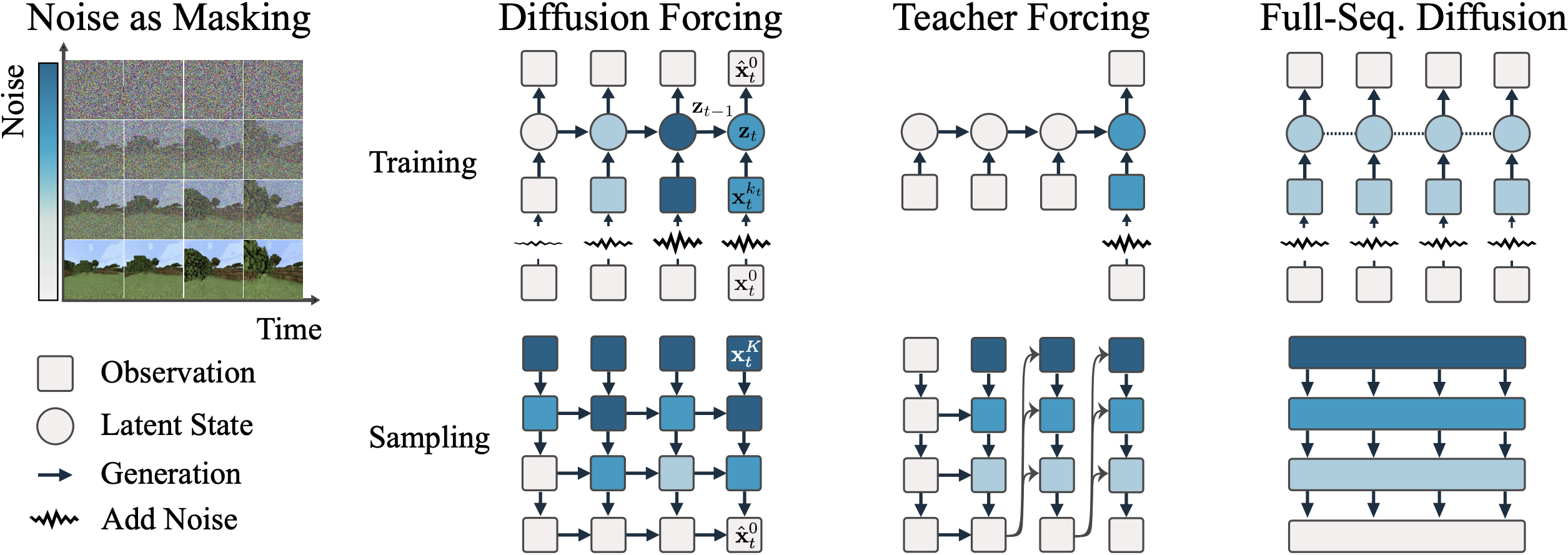
Conditioning: When
people extend a sequence diffusion model to longer length than
it's trained on, conditioing by replacement is often used. In
his paper "Video Diffusion Models", Johnathan Ho discusses why
this is wrong. Instead, diffusion Forcing tells the model to
treat context tokens as clean and future tokens as noisy, which
is a more natural way to do conditioning but we haven't explored
this in detail.
Noise as masking:
Noise as masking achieves fractional masking of tokens instead
of a discrete binary masking. This is general enough to be put
in many self-supervised learning methods like MAE. Since adding
by noise have interesting interpretations on frequency domain,
this could be interesing to explore.
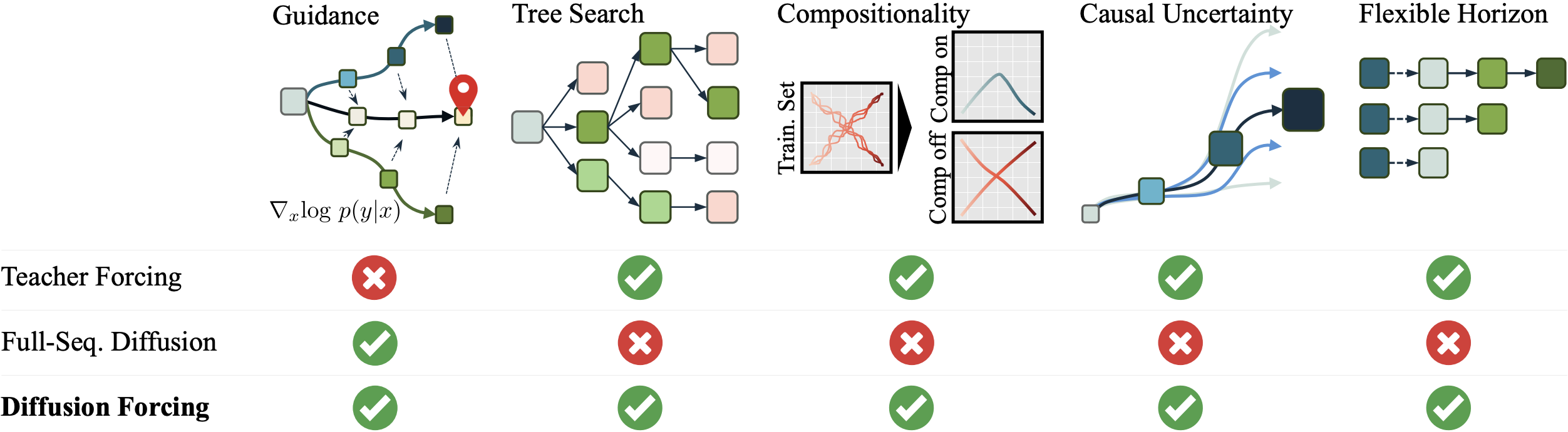
Compositionality:
In our paper, we show compositionality can be achieved by
controlling the history length. However, with noise as masking,
it's possible for the model to figure out when to ignore
uncessary history and only condition on shorter horizon itself.
Non-causal version:
Diffusion Forcing is causal as in this paper because causality
is important for decision making. However, the idea of noise as
masking is applicable in non-causal models as well. In fact, you
can potentially train a non-causal version and make it causal at
sampling time! To do so, you can just mask entries that you
don't want a prediction to see with pure gaussian noise.
Alternative Guidance:
In our paper's proposed decision making framework, we did
guidance on observation to keep the setting closer to diffuser.
However, we also proposed a version where we do guidance on
learned reward but haven't explored it in the paper.
Noise scheme:
The idea of independent noise level per token is designed to be
general, but not necessarily optimal for every task. E.g. It
could retain too much redundency if the data is very locally
correlated on time axis. This can affect the overall
signal-to-noise ratio. It's interesting to explore different
noise schemes.
Next few token prediction:
Next few token prediction is only used in our planning
experiment, and video experiment is still next-token. It didn't
work super well in RNN version but we find it to work very well
in our transformer version of code. One observation we find is
that when using a causal model, doing next few token prediction
can lead to inconsistency if the "few" is very big. This doesn't
happen as much for non-causal model. There are interesting
scientific questions to study why.
Latent & DiT version:
We released a 3D Unet Version of Diffusion Forcing after the
release. However, Diffusion Forcing shall be applicable to DiT
as well, causal or non-causal. In addition, the stablization
scheme makes more sense in latent space with VAE, because
corruption on pixel is not necessarilty gaussian while that on
VAE latent shall be closer to gaussian.